Best LLM for reasoning in 2026: ARC-AGI-2 benchmark results
- Jan 29
- 3 min read
Updated: Mar 27
Ever wondered which AI model is best at real reasoning?
Reasoning benchmarks are tests that score AI models on tasks that require learning, not memorizing. Think of them as a leaderboard for fluid intelligence.
Most benchmarks reward knowledge.
ARC-AGI-2 rewards adaptability.
That is why ARC-AGI-2 is one of the most important benchmarks right now for measuring true general reasoning.
Why should you care?
Reasoning benchmarks are not just academic.
They are one of the best proxies we have for:
general problem solving
learning new rules fast
pattern recognition
adapting beyond training data
So if you care about where AI is actually heading, this benchmark matters.
Not sure which AI model to pick?
Read our full guide to the best LLMs
Which LLM is best at reasoning in 2026?
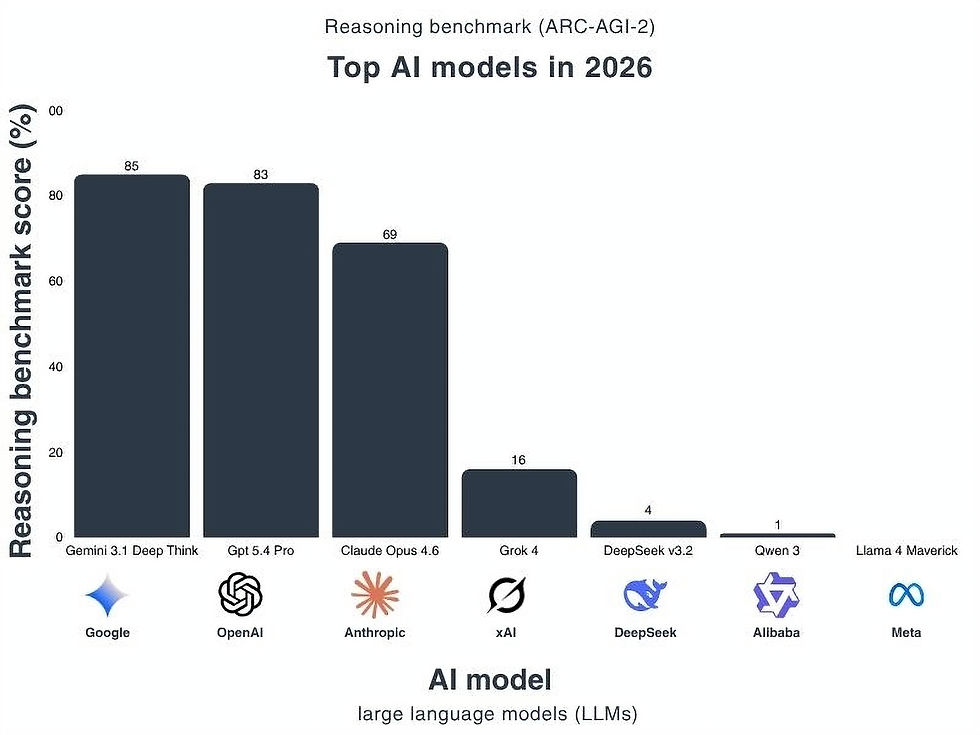
The newest ARC-AGI-2 results show a very different frontier compared to 2 months ago.
The frontier has moved up
Google’s Gemini 3.1 Deep Think currently holds the highest reported score at 85%.
Close behind is OpenAI GPT-5.4 Pro at 83%.
Both models represent a massive jump compared with earlier ARC-AGI-2 results. For the first time, systems are solving the majority of tasks on the benchmark rather than struggling below 50%.
Claude remains competitive but behind
Anthropic’s Claude Opus 4.6 scores 69%.
That is still a strong result, but there is now a noticeable gap between the two leaders and the rest of the field.
Most models still struggle
After the top three, performance drops sharply.
Grok 4: 16%
DeepSeek v3.2: 4%
Qwen 3: 1%
Llama 4 Maverick: 0%
This highlights something important about ARC-AGI-2.
Even with rapid progress at the frontier, most systems still fail on the majority of tasks.
The gap between frontier models and the rest is huge
ARC-AGI-2 is designed to reward generalization, not memorization.
The newest results show that only a handful of models can consistently infer the hidden rules behind these puzzles.
Everyone else is still close to random guessing.
That is why this benchmark continues to be one of the clearest signals of where real reasoning progress is happening.
What is the ARC-AGI-2 benchmark?
ARC-AGI stands for Abstract Reasoning Corpus for Artificial General Intelligence.
It was first proposed by François Chollet as a test of fluid intelligence.
The goal is simple:
tasks that humans solve easily
tasks that AI cannot brute-force
minimal reliance on training data
ARC-AGI-2 is the second generation of this benchmark, released in 2025.
It is harder than ARC-AGI-1, while staying easy for humans.
Every task was solved by at least two humans in under two attempts.
What makes ARC-AGI-2 different?
Most benchmarks test “PhD-level knowledge.” ARC-AGI tests the opposite.
It focuses on simple puzzles that require:
learning a rule from examples
applying it in a new setting
generalizing quickly
This exposes the gaps that scaling alone does not fix.
ARC-AGI-2 also measures efficiency. The ARC Prize team now reports cost per task, not just accuracy. Because intelligence is not only solving problems. It is solving them efficiently.
Humans solve tasks for roughly $17 each. Some AI systems need hundreds of dollars per puzzle. That gap is the real signal.
Ready to apply AI to your work?
Benchmarks are useful, but real business impact is about execution.
We run hands-on AI workshops and build tailored AI solutions, fast.



This article offers a clear and informative look at the ARC/AGI‑2 benchmark, explaining its role in evaluating artificial general intelligence performance in a way that feels accessible rather than overwhelming. The way it outlines what the benchmark measures and why it matters helps readers understand how progress in AI is assessed with rigour and transparency. In the same way that understanding unilever supply chain challenges requires well‑structured explanation to make complex operational issues easier to grasp, this post shows how thoughtful organisation and clarity can help readers connect with advanced technical topics, and platforms like Native Assignment Help also reflect this by presenting detailed subjects in a logical and approachable way that supports learner confidence and comprehension.